TL;DR: A multi-scale, point-based neural radiance field that allows for leveraging point cloud regardless of it's low quality (e.g., LIDAR with large incomplete space).
Note: Trained with sparsely sampled frames from KITTI-360 dataset and rendered with densely interpolated frames.
Paper

PointNeRF++: A multi-scale, point-based Neural Radiance Field.
Weiwei Sun, Eduard Trulls, Yang-Che Tseng, Sneha Sambandam, Gopal Sharma, Andrea Tagliasacchi, Kwang Moo Yi
arXiv.
@InProceedings{sun2023pointnerfpp,
title = {PointNeRF++: A multi-scale, point-based Neural Radiance Field},
author = {Weiwei Sun, Eduard Trulls, Yang-Che Tseng, Sneha Sambandam, Gopal Sharma, Andrea Tagliasacchi, Kwang Moo Yi},
booktitle = {European Conference on Computer Vision},
year = {2024}}
Abstract
Point clouds offer an attractive source of information to complement images in neural scene representations, especially when few images are available. Neural rendering methods based on point clouds do exist, but they do not perform well when the point cloud quality is low---e.g., sparse or incomplete, which is often the case with real-world data. We overcome these problems with a simple representation that aggregates point clouds at multiple scale levels with sparse voxel grids at different resolutions. To deal with point cloud sparsity, we average across multiple scale levels---but only among those that are valid, i.e., that have enough neighboring points in proximity to the ray of a pixel. To help model areas without points, we add a global voxel at the coarsest scale, thus unifying ``classical'' and point-based NeRF formulations. We validate our method on the NeRF Synthetic, ScanNet, and KITTI-360 datasets, outperforming the state of the art by a significant margin.
Method
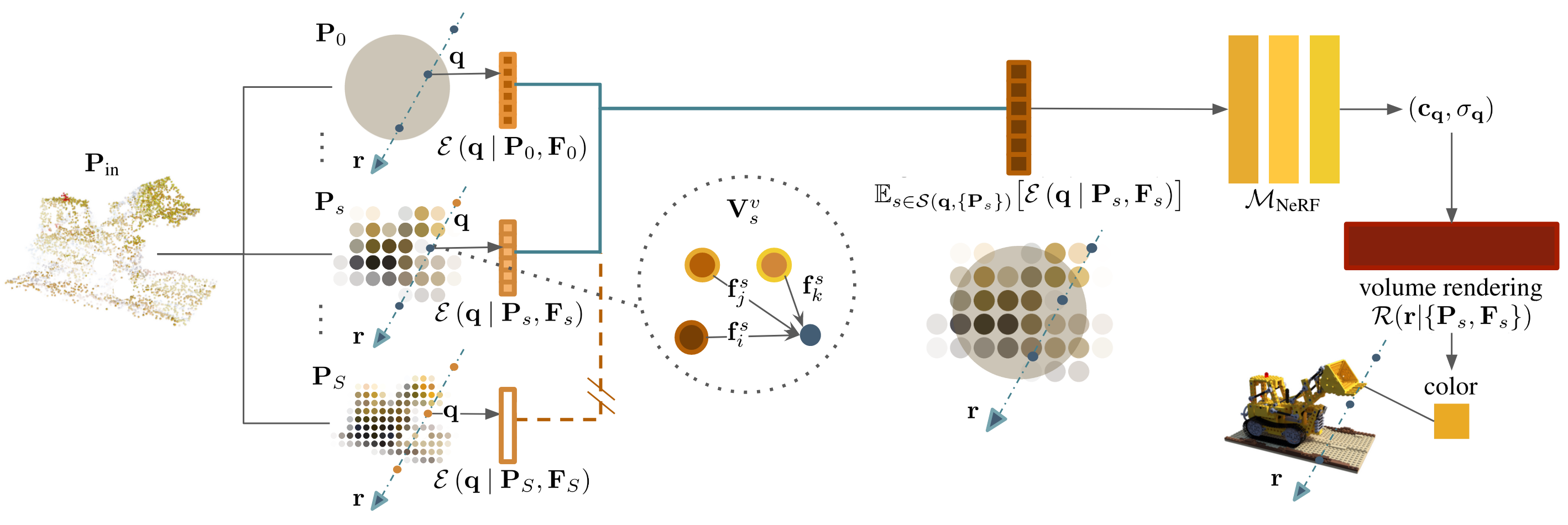
Overview: given an input point cloud, we aggregate it over multi-scale voxel grids. For clarity, we draw the voxel grids in 2D. We then perform volume rendering based on points, relying on feature vectors stored thereon, which we aggregate across multiple scales. Importantly, when aggregating across scales, we only take into account 'valid' scales---denoted with the solid lines and illustrated as the two overlaid scales in the middle ---naturally dealing with incomplete/sparse point clouds. The coarsest scale is a single, global voxel, equivalent to standard NeRF (i.e., not point-based).
Nerf vs PointNeRF vs PointNerf++(ours)
We compare PointNeRF++(ours) with baselines including NeRF and PointNeRF. We show that our method achieve significantly better results than both baselines. Note that we can move slider left and right to see the comparison.




More Rendering Results
| Camera frames (Left camera) in KITTI-360. | ||
| Point cloud at image's viewpoint |
PointNeRF | PointNeRF++ (Ours) |
| Densely interpolated frames in KITTI-360 | ||
| Point cloud at image's viewpoint |
Depth map | Color |
| More frames in ScanNet. | |||
| Point cloud at image's viewpoint |
PointNeRF | PointNeRF++ (Ours) | Ground Truth |
| Rendering across scales | |||||||
| Point cloud at image's viewpoint |
Level 0 (Global level) |
Level 1 | Level 2 | Level 3 | Level 4 (Fine level) |
All levels | Ground Truth |
Acknowledgements
This work was supported in part by the Natural Sciences and Engineering Research Council of Canada (NSERC) Discovery Grant, NSERC Collaborative Research and Development Grant, Google, Digital Research Alliance of Canada, and Advanced Research Computing at the University of British Columbia.
This website is adapted from the template was originally made by Phillip Isola.
This template was originally made by Phillip Isola and Richard Zhang for a colorful project, and inherits the modifications made by Shangzhe Wu
and Canonical Capsules.
Video comparison is adapted from ZipNeRF.
Image slider script is adapted from Dics.
The code can be found here.